The Levenshtein distance in production
You might have heard about the Levenshtein distance while in college or while preparing for tech interviews. It is the famous edit distance problem. It is one of those must-try Dynamic Programming challenges.
You still there? even after I said the words “Dynamic Programming”? haha. Good! Because unlike you, I am good at running away from it; most of the time. But I am kind of sitting down to learn + practice this stuff now.
This amazing book played a major role in making this topic a little less scary for me. What intrigued me the most is the spot where the author tries to explain some practical applications for dynamic programming.
Among all the applications I read there, two of them were practical and in-fact something that I use almost every day. One is in diff tools like git diff to compare text and another one is in spell checkers to figure out the closest matching words to the spelling we typed.
That’s great! Those are some “open up and read the source code” kind of things. Guess what, I love those kinds of things. Instead of sinking into interview prep materials one after another, I might take this as a fun chance to learn some code that is used in the wild!

So let us learn about the problem, the way it is implemented in some open-source software (which are used by a lot of people - like a really really big number).
Problem statement
I am going to copy-paste from Wikipedia to help me here.
the Levenshtein distance is a string metric for measuring the difference between two sequences
Basically, it is a way of comparing two strings.
Informally, the Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions, or substitutions) required to change one word into the other.
Consider spell checkers. When you type something, the spell checking software should suggest you which is often a valid English word with a minimal Levenshtein distance.
Git
Here is the cool thing: Git uses dynamic programming. Apart from the mention in that book regarding git diff, I found an elegant use-case of Levenshtein distance in some other part of git.
Here is how I found this out. I usually end up typing the git sub-commands wrongly at least once per day. Git would intelligently understand what I am trying to type and output a suggestion like this
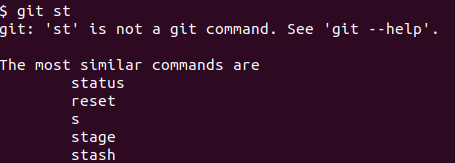
So, what is git doing here? It is just spell-checking the sub-command I typed in by comparing it against all the valid git sub-commands. Cool, at that point in time I was like “I think git might be using the Levenshtein distance to do this”.
Then I started greping “The most similar commands are” in the git source code to dig deep into the source code.
Bingo! Of course it uses the Levenshtein distance :)
1 | int levenshtein(const char *string1, const char *string2, |
Here is the header file that declares the function and the c implementation of the logic.
It gets called in help.c, the source file responsible for showing help message in git.
The function first loads all the valid sub-commands of git (including the aliases we have - just knew this fact while digging the source).
1 | load_command_list("git-", &main_cmds, &other_cmds); |
After that, it computes the Levenshtein distance and decides which command to suggest.
One interesting thing that I noted is how practical the code is. If we just see it as an interview prep thing, we might just write a recursive implementation and be done with it (which is usually simpler than writing an iterative approach). But in real-world a recursive approach might result in a stack overflow. Hence, an iterative approach to solving this problem is much more desirable.
Also, see the level of optimization, they do! A comment from the source below:
1 | * The idea is to build a distance matrix for the substrings of both |
At any given point of time, they are just using 3 rows of the memo table to figure out the answer, instead of keeping the entire memo table in memory.
1 | int levenshtein(const char *string1, const char *string2, |
Where else?
After a while of staring at git source code today with a little bit of struggle reading C and getting into all the details of the solution, I wanted to read the implementation in some other programs as well. There are lot of command-line tools and I have noticed a lot of the good ones support this spell check feature.
In fact this kind of functionality should typically be provided by the sub-command parsing cli library so that it is available more easily to cli writers. I was right again! Since I am into Go recently, I tried searching through a famous command line parser library for Go called Cobra.
Cobra is used in many Go projects such as Kubernetes, Hugo, and Github CLI to name a few
Cobra
Cobra contains a reference to Levenshtein distance in the README file.
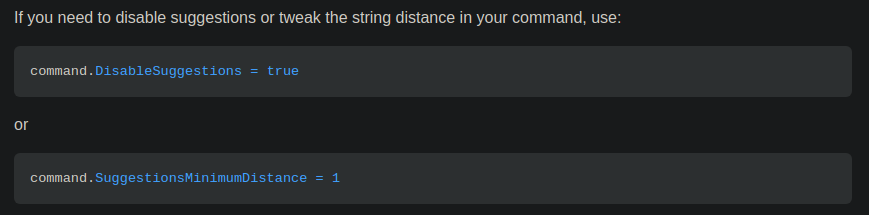
Cool, it even has the configuration to choose the distance based on which the suggestions should be picked.
Now, on to the source code. It is written as a simple function.
1 | // ld compares two strings and returns the levenshtein distance between them. |
It is an iterative solution. To understand it better, I copy-pasted the function onto the Go playground and started playing around with it.
1 | func main() { |
The answer correctly came up as 1. (just 1 deletion operation of b)
Now let me try to go line by line and try to figure out what is happening.
We accept two input strings s and t. We ignore the cases if the flag is set.
1 | if ignoreCase { |
After that, we create a two-dimensional array called d to act as the memo table.
1 | d := make([][]int, len(s)+1) |
Now to visualize things, I am adding a little function that prints the memo table.
1 | " a c |
Next, we initialize the first column of every row with the value of the row index.
1 | for i := range d { |
Now the table becomes
1 | " a c |
After that, we initialize the first row of every column to the value of the column index.
1 | for j := range d[0] { |
That yields
1 | " a c |
That completes the base case: “When you start with an empty string and start building the strings, the operation count would just increase by one as it involves only one insertion operation.
Now, we start filling the inner parts of the table.
1 | for j := 1; j <= len(t); j++ { |
Ah nice, that felt so easy. If the row and column alphabet value are the same, then we don’t need to perform any operation and hence we get to use the last counted operation value by looking at the diagonal.
1 | if s[i-1] == t[j-1] { |
For example: Here is the final table. Notice how (a,a) is filled up with looking at the diagonal (",").
1 | " a c That is because, when the resulting string is already `a` there is no need to perform any |
If the alphabets differ, then we need to perform one of the operations (insert, remove, replace) to arrive at the desired alphabet. It seems like the way we figure out this is by finding the minimum of the adjacent cells (that are already filled) and adding 1 to it (to effectively say that we need to perform one more operation)
1 | min := d[i-1][j] |
So, at last, we return the last cell of the matrix.
1 | return d[len(s)][len(t)] |
It may not be obvious of what is going on especially in the last part of the code explanation above (apologies for not trying to explain that here). The recommendation for it is to watch/read some tutorial on how the memo table is filled up like this. The point of this explanation is to share how cleanly those ideas behind filling up the memo table is implemented in the library code.
Closing
The main difficulty I feel here is the arrival of the idea behind the memo table. What should be the columns and rows? What should be the values that should be filled up in the cells? How do we compute the value of each cell?
Apart from the interview prep point of view, knowing these techniques (just knowing that these kinds of techniques exist in the world) can be a nice addition to one’s problem-solving toolbox. The next time you are working on a cli app or some other app that needs spell check like suggestions, you know what to do!