Enter the JVM: Part 2
I am glad that I am continuing my journey of reading the JVM specification and learning about it. If you had missed the first part of this series, you can read it from here. I read the Chapter 2: The Structure of the Java Virtual Machine last night and I came across quite some interesting and basic things.
First of all, the structure of the JVM is itself a beauty. I usually hear of two words, “stack and heap” whenever someone tries to explain how a program is running (from the days of C#ing). Reading the spec made it very obvious and It is exciting to know how exactly those two are used for running programs on the JVM.
JVM Types
This is different from the types in Java Programming Language. I guess that all the JVM languages boil down to use these types when executing over the JVM.
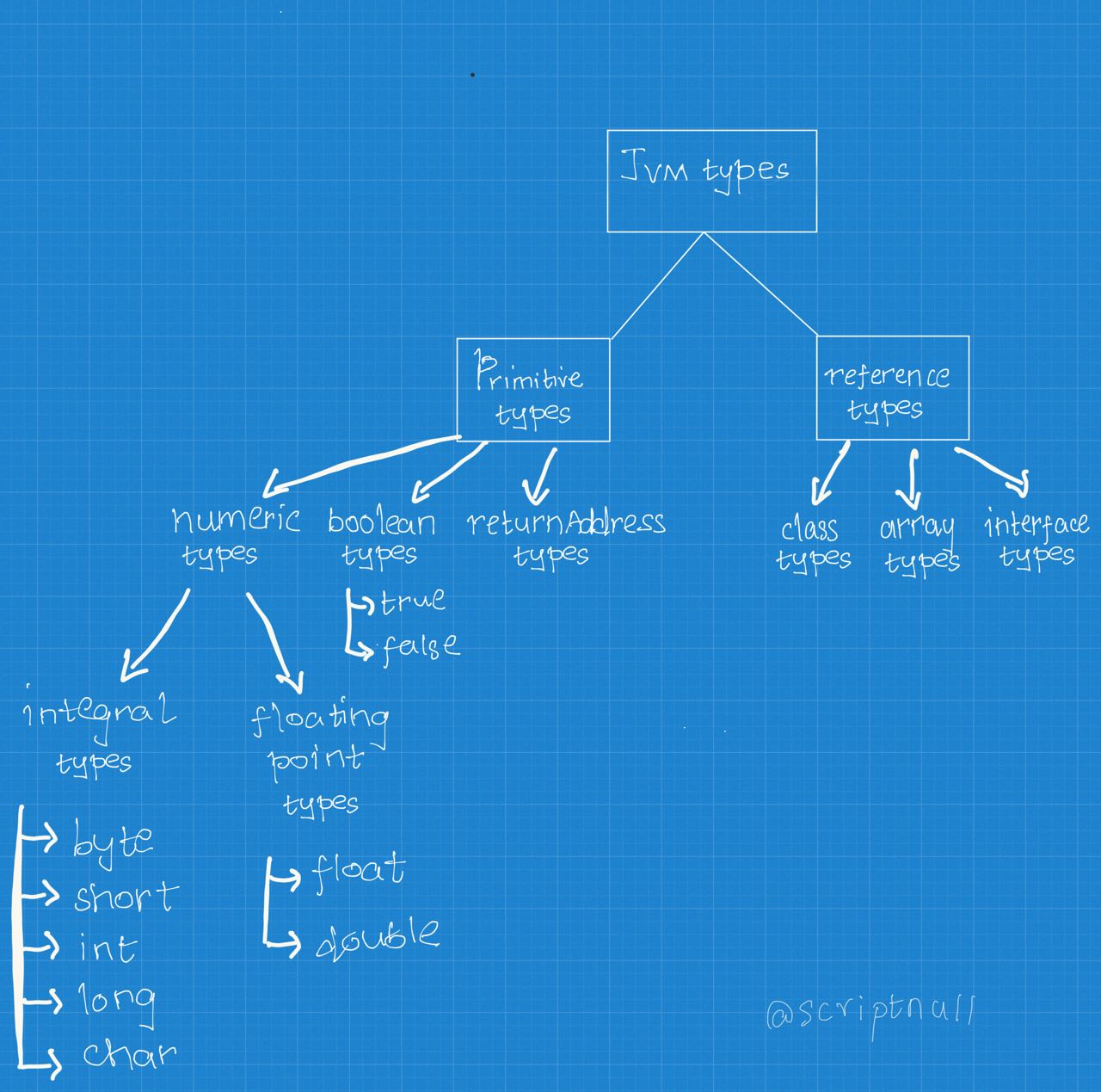
Here are some key takeaways and lessons that I learnt,
All the integral types except
charare n-bit signed two’s-complement integers, whose default value is zero. Corresponding n values are- byte: 8 bits
- short: 16 bits
- int: 32 bits
- long: 64 bits
At this point, I am curious to learn What are two’s complement integers?
charis actually an integral type. The spec clearly says
char, whose values are 16-bit unsigned integers representing Unicode code points in the Basic Multilingual Plane, encoded with UTF-16, and whose default value is the null code point (‘\u0000’)
At this point, I am curious to know the difference between UTF-8 and UTF-16. Why new programming languages like Go are preferring UTF-8 over UTF-16?
floatanddoubleare stories of their own. Their implementation is based on a separate specification called IEEE Standard for Binary Floating-Point Arithmetic (ANSI/IEEE Std. 754-1985, New York). It should be worth to take a look at IEEE 754, as it will help understandfloatanddoublein a better sense. (Not sure if it is available for free though!)returnAddresstype is the only type that does not have corresponding type implementation in the Java Programming Language. From the following statement in the spec, I could understand that it is used internally in JVM.
The values of the returnAddress type are pointers to the opcodes of Java Virtual Machine instructions.
- Default value of a reference type is
null.
Run-Time Data Areas
In the part 1, I mentioned that the JVM spec does not mandate the memory layout of run-time data areas and I was not really sure of what that meant. After going through the Run-Time Data Areas section, I got some idea of it.
Data areas are areas that hold data in JVM. It seems like the spec does not mandate the memory layout, by which I guess it does not care about the storage medium used to store or the way in which data is arranged on those. (fuel to fire 🔥 : Is it possible to use cloud storage like Amazon S3 to implement the run-time data areas of a JVM for fun? But it does not really have any use and would be very slow. PS: It is just mid night and I am in half-sleep and I am not responsible for what I suggested just now 🌙 )
Some of these data areas are created on Java Virtual Machine start-up and are destroyed only when the Java Virtual Machine exits. Other data areas are per thread. Per-thread data areas are created when a thread is created and destroyed when the thread exits.
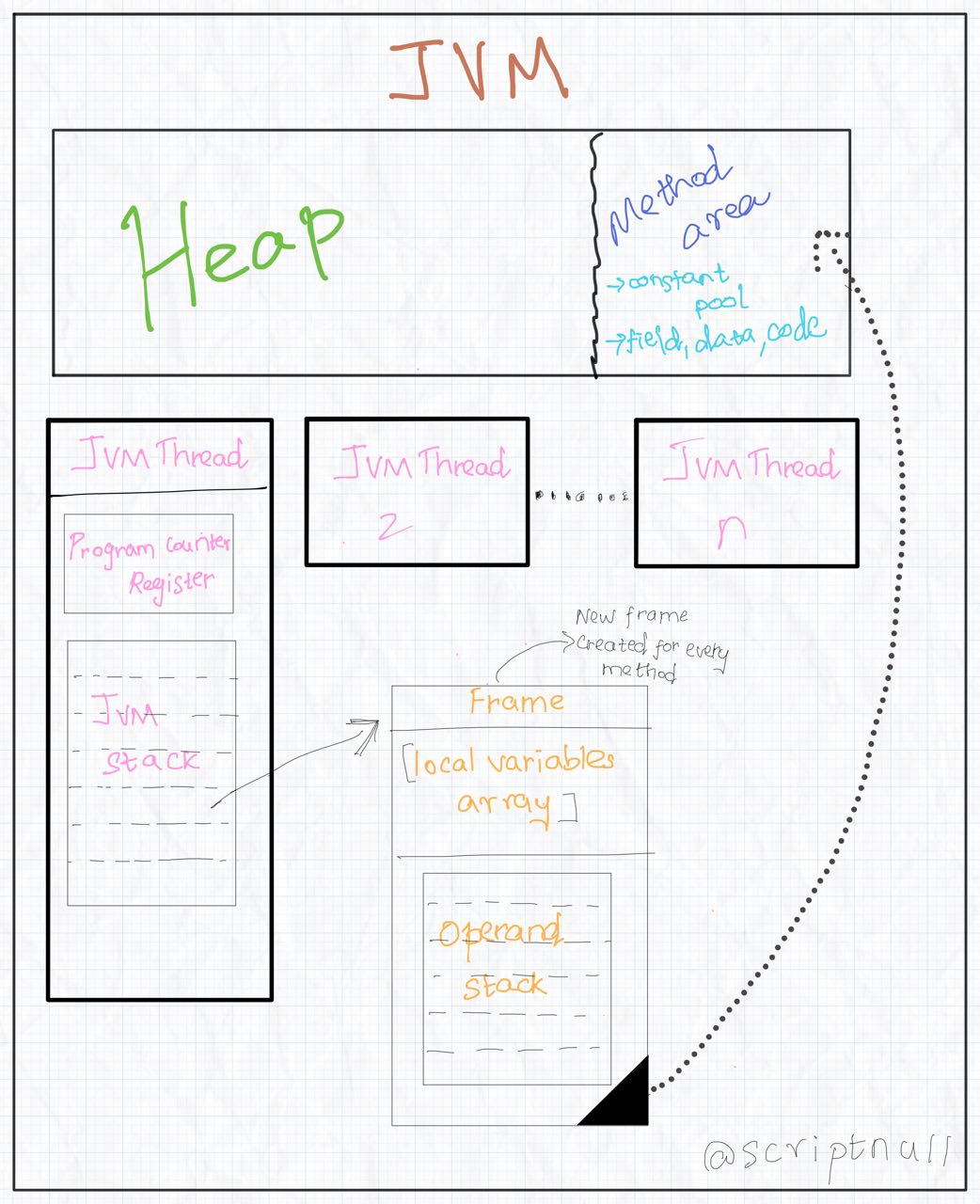
Various run-time data areas mentioned in the spec are,
- Program Counter Register - Created for each JVM thread. Points to the current instruction address being executed.
If that method is not native, the pc register contains the address of the Java Virtual Machine instruction currently being executed. If the method currently being executed by the thread is native, the value of the Java Virtual Machine’s pc register is undefined.
JVM Stacks - Created for each JVM thread. Every new method call creates a new frame, which is pushed to JVM stack if it invokes another method.
Heap - Shared among all the JVM threads.
The heap is the run-time data area from which memory for all class instances and arrays is allocated.
- Method Area - Shared among all the JVM threads.
It stores per-class structures such as the run-time constant pool, field and method data, and the code for methods and constructors, including the special methods used in class and interface initialization and in instance initialization
- Native Method Stacks - Depends on the implementation of JVM.
An implementation of the Java Virtual Machine may use conventional stacks, colloquially called “C stacks,” to support native methods (methods written in a language other than the Java programming language). Native method stacks may also be used by the implementation of an interpreter for the Java Virtual Machine’s instruction set in a language such as C. Java Virtual Machine implementations that cannot load native methods and that do not themselves rely on conventional stacks need not supply native method stacks. If supplied, native method stacks are typically allocated per thread when each thread is created.
That’s it for today, I guess. I am not able to go into the details of Frames, but all I could say is
A frame is used to store data and partial results, as well as to perform dynamic linking, return values for methods, and dispatch exceptions.
I hope to demonstrate how they operate while visiting the jvm instructions in detail. With that being said, I am ending this post with some of the questions for which I would like to find answers for,
- Two’s complement Integer? One’s complement?
- What is Big Endian?
- UTF-8 Vs UTF-16?
- How exactly are Native methods coming into play in JVM?